Edge AI vs Cloud AI: The Real Cost Comparison Nobody Talks About

Lou Farrell
Senior EditorEdge AI and cloud AI are both cost-effective ways to run a facility, but the complex reality of industrial operations compels businesses to go beyond exclusive approaches. Latency penalties, outage exposure, compliance risk, life cycle workflows and other hidden costs can change the expense numbers fast. The most promising outcomes usually come from a hybrid model that assigns decisions to the edge and analysis to the cloud.
The Case for Processing at the Source With Edge AI
Edge AI processes data on or very near the asset that generates it. In industrial settings, this refers to models running on gateways, programmable logic controller-adjacent compute, hardened IPCs or smart sensors installed on pumps, compressors, heat exchangers or switchgear.
Its core financial value is time. To get the fastest and most predictable response times during unexpected issues, such as pressure spikes or signals of machine damage, the system makes decisions right on the device itself, avoiding round-trip delays to a remote server.
Where Edge Delivers Value
In places with poor or costly internet, like remote industrial sites, edge AI offers a major advantage. It reduces expensive data fees by analyzing data right where it's collected, while keeping local systems responsive and in control.
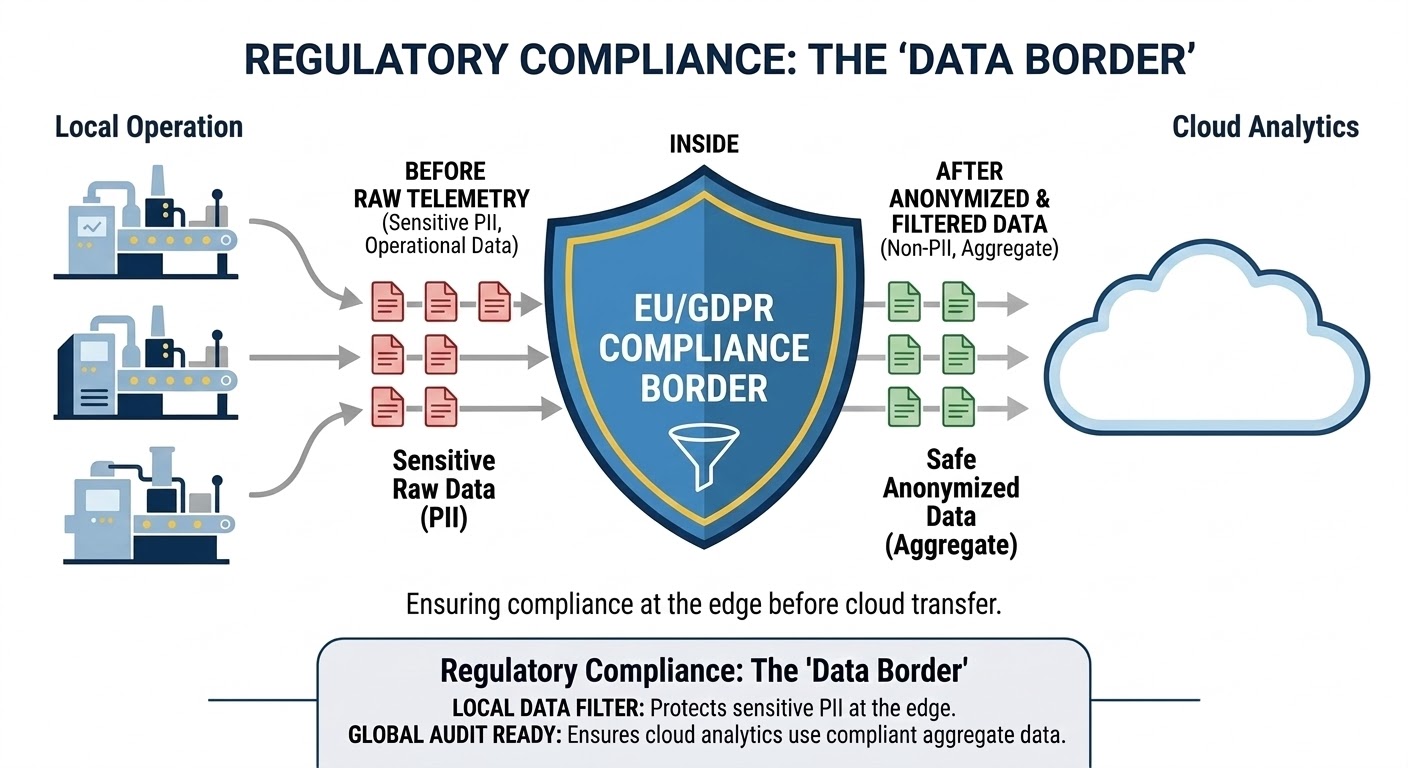
It also supports data minimization, so sensitive operational telemetry and process signatures can remain on-site with minimal exposure when data crosses organizational boundaries. This aligns with the European Union's industrial data governance and portability initiatives. For instance, on-site processing allows a valve on a remote pipeline to respond instantly to vibration or pressure alerts. This automatic reaction can immediately stop a small irregularity from causing a major, costly shutdown.
Limitations of an Edge-Only Model
The up-front cost for an edge-exclusive system doesn't tell the whole story. The initial bill covers the devices, but the true expense comes later from the ongoing effort to maintain the software on every unit. These growing pains usually manifest after the rollout in the form of secure provision and patching across sites, model drift validation, audit trails, version pinning and rollback plans. Fragmented local data islands that block fleet-wide benchmarking and learning can also prove expensive later.
All such burdens also interact with regulatory expectations around security controls. ENISA's 2025 NIS2 technical implementation guidance emphasizes the need for structured measures and verifiable implementation. These can be challenging to achieve if controls must be proven across a large edge fleet.
Finally, edge compute limits have a considerable financial impact. Smaller footprints may constrain feature engineering and multisite correlation. To compensate, teams tend to over-provision hardware or accept lower-end models at the edge, eventually draining the deployment's long-term value.
Evaluating edge and cloud expenses involves comparing human labor against network billing. Having a purely edge fleet consumes expensive engineering hours to manually patch firmware, troubleshoot field devices and physically replace degraded hardware. On the other hand, relying on cloud servers shifts the financial burden away from site engineering and directly into escalating data fees, continuous ingress charges and premium bandwidth subscriptions.
Understanding Cloud AI and Centralized Power
Cloud AI processes data in a centralized infrastructure with elastic compute and storage capabilities. In industrial AI applications, this means aggregating operational data, historian extracts, maintenance events and quality signals, then using managed services to run training, simulations or larger-scale inference.
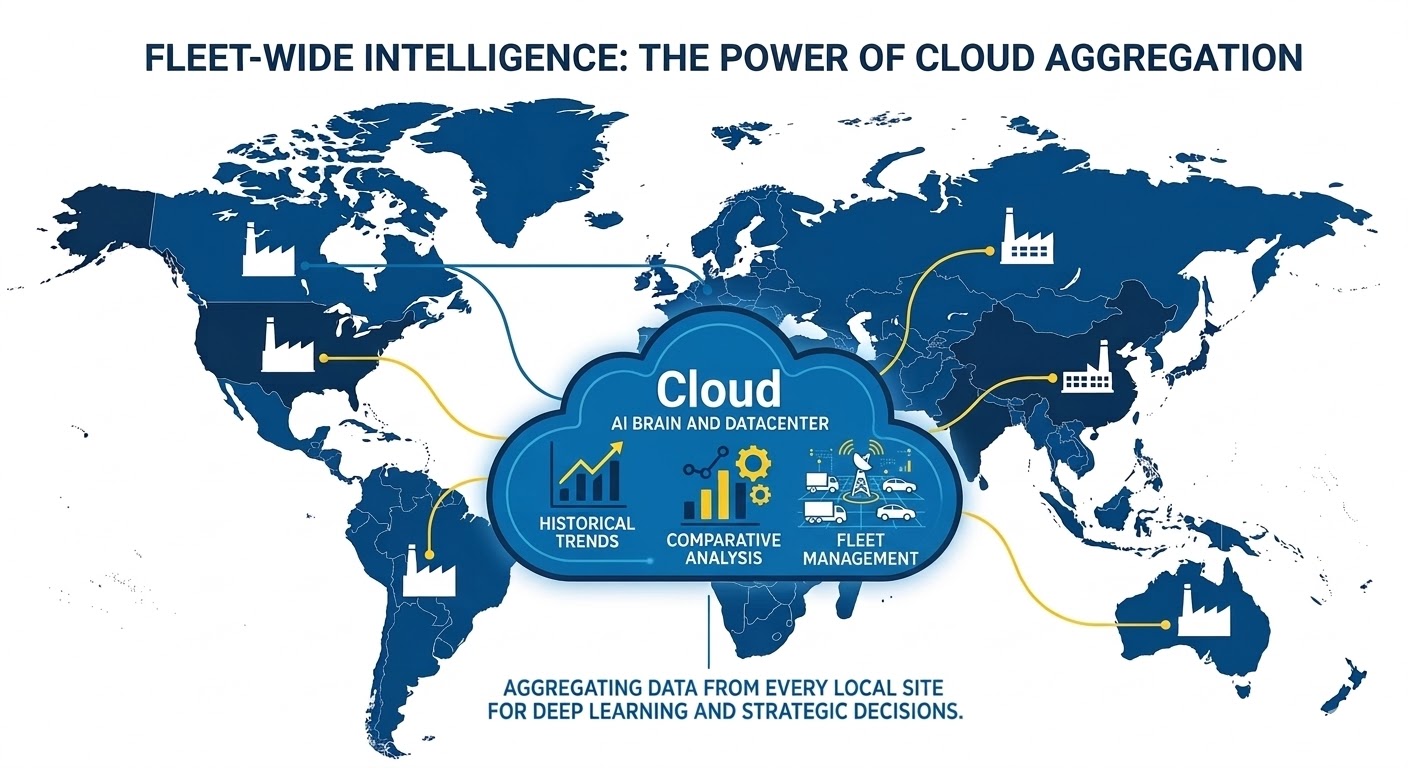
Cloud's main advantage is its breadth, as it can combine multisite data, retain longer histories and run heavier analytics that would not fit on edge hardware. This is particularly true when models evolve rapidly or require retraining cycles to handle large datasets.
The Strengths of Centralized Analytics
Cloud AI excels at scaling up and scaling out, especially with a pay-as-you-go model that reduces up-front spend. This is great for programs that start with uncertain scopes. This also lets teams test improvements and reliably roll out the same process across locations. With shared data, they can connect the dots between failures, seeing how the same type of equipment performs well under various conditions, usage levels or even with different operators.
The cloud is also where modern optimization naturally fits, as AI can adjust automated workflows after analyzing supply and demand data, which requires access to broad datasets to run more intensive optimization.
The Risks of a Cloud-Only Model
Cloud-only looks seamless and straightforward until industrial data physics and operational risk show up in the budget. The hidden costs surface from moving data, waiting for decisions and absorbing the consequences when connectivity fails.
The two cost drivers that regularly surprise industrial teams are data transfer exposure and degraded operations following a loss of connectivity. Cloud data movement costs can influence vendor strategy and architecture choices. In Europe, for example, the EU Data Act required providers to adjust transfer fees and encouraged users to switch to European providers to improve data sovereignty. In addition, cloud-only intelligence pauses when a site fails to reach the cloud, leading to delayed alarms, slower triaging or a loss of optimization routines.
Network latency can also critically affect industrial environments. A delay in identifying anomalies can turn a warning into actual equipment damage or a safety issue. By the time the cloud sends back an answer, it might be too late to do anything about it.
Quantifying this latency penalty also reveals severe financial consequences. For example, a delayed response to a failing pump bearing can escalate a simple five-part replacement into a catastrophic motor failure costing $45,000 in hardware and $120,000 in unplanned downtime. Instantly detecting the acoustic anomaly at its source can prevent cascading failure.
Breaking data regulations is another big concern. The General Data Protection Regulation imposes steep penalties for managing data improperly, and these fines can be particularly harsh for industrial businesses.
The New Standard for Industrial AI: The Hybrid Model
A hybrid model combining edge AI and cloud AI assigns responsibilities based on time sensitivity, data gravity and governance needs.
At the edge, models handle fast decisions, such as anomaly detection, safety thresholds, local optimization and control-adjacent alerts. The edge also compresses the firehose, so instead of streaming raw high-frequency signals continuously, it transmits features, event summaries and exception windows.
In the cloud, centralization enables thoughtful decisions, such as multisite benchmarking, predictive maintenance modeling, retraining, digital twin calibration and cross-asset correlation. As it obtains higher-value data, using the cloud can reduce bandwidth spend while improving learning across sites.
The hybrid structure aligns with the EU data portability direction. Because the Data Act emphasizes industrial data accessibility and switching expectations, industrial programs are nudged toward architectures that avoid unnecessary lock-ins.
Here’s an at-a-glance take on how they stack up against each other:
Feature | Edge | Cloud | Hybrid |
Latency | Milliseconds | Seconds to minutes | Context-dependent |
|---|---|---|---|
Initial cost | High hardware capital | Low entry barrier | Moderate distributed |
Long-term scalability | Hardware limited | Virtually unlimited | Elastic processing |
Regulatory risk | Low data exposure | High transfer risk | Compartmentalized |
Hybrid AI in Action with Waltero
The Waltero ecosystem fits the hybrid pattern in a practical, industrial form. At the edge, its W-Sensor supports real-time monitoring and local alerting near critical assets. In industrial contexts, such as water and wastewater pumping, heating networks or energy distribution equipment, local detection can quickly flag abnormal vibration or operational-state changes to support operational response.
From there, the summarized data can flow to the cloud layer, where Mimir supports historical analysis, longer-horizon modeling and fleet-wide visibility. By sending events and features rather than raw streams, a program can reduce transfer cost and decrease the amount of sensitive telemetry exposed beyond the site's boundary. Site-level teams get to act on any signal immediately, and central teams receive a consistent dataset for reliability analysis across facilities in different regions.
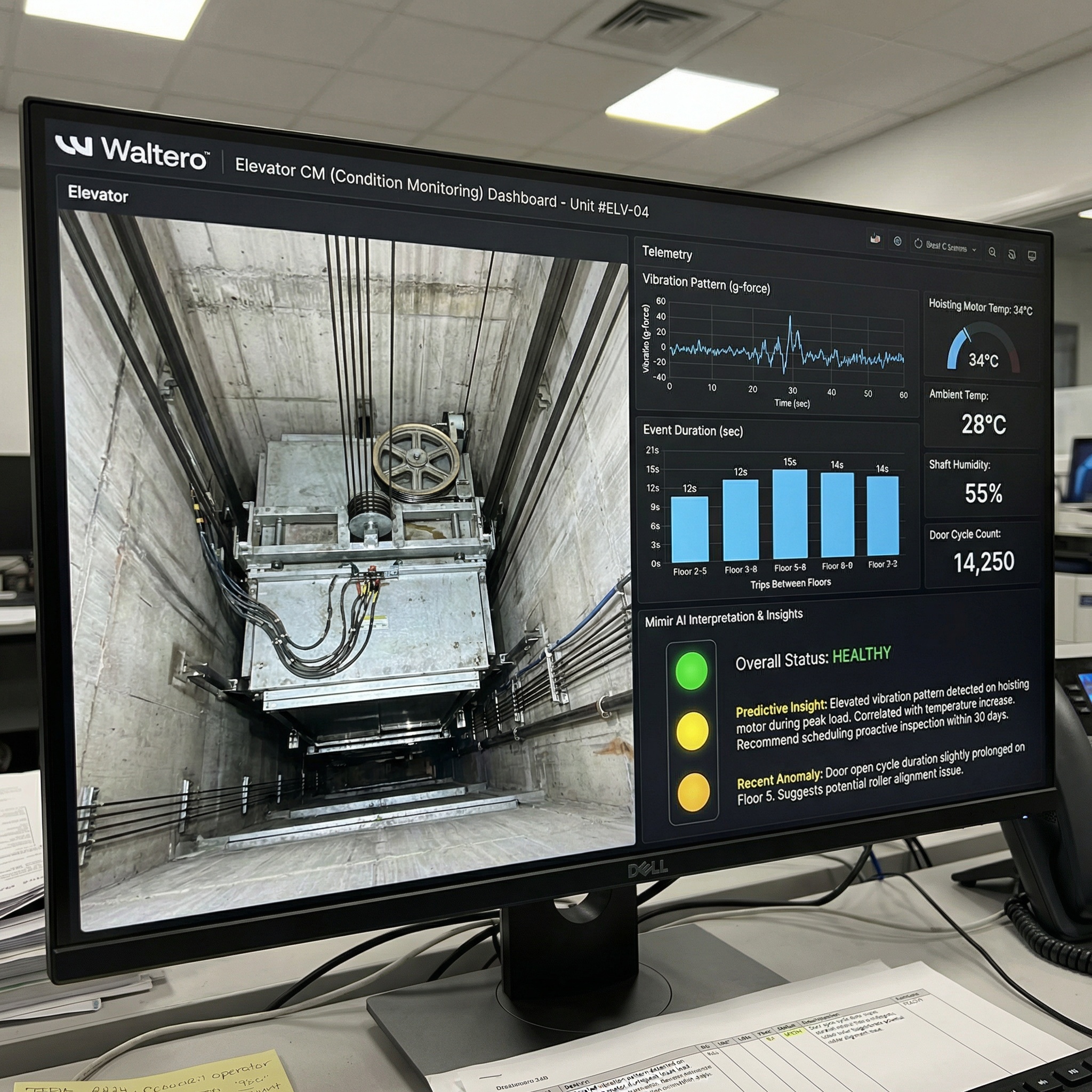
Integrating local processing with central oversight is the answer to model drift. As the accuracy of local algorithms naturally degrades, mainly due to changing physical and environmental conditions, the central server can check aggregated performance metrics to detect performance drops. Engineers then train a corrected algorithm centrally and distribute the new parameters to field equipment through over-the-air updates. This automated pipeline maintains fleet-wide accuracy and eliminates expensive physical site visits.
Planning for a Successful Hybrid Strategy
While hybrid adoption does solve technical shortcomings, the success of any rollout is mostly an organizational issue. Some resistance can be expected in industrial environments because new systems alter routines, escalation paths and accountability, but planning for that response reduces program drag.
One strategy is to form cross-functional teams that include operations, IT, engineering and customer-facing roles. This approach keeps decisions practical and relevant to the plant floor without compromising data security. The best way to reduce costs is to separate the time-sensitive decisions that need to be made on the spot from those that can wait for deeper insights from the cloud.
Another solution is to standardize the processes for updating and evidence collection so edge fleets remain maintainable and security controls remain demonstrable and compliant with EU guidelines.
Why Long-Term Impact Is the Only Cost That Matters
Industrial managers are unlikely to regret investing in gathering insights, but they will regret paying for data that arrives too late, fails during a network event or creates a compliance problem. Edge-only programs pay for fleet operations and lose cross-site learning, while Cloud-only programs pay for transfer, latency penalties and outage consequences.
A hybrid model is the ideal path to reduce wasted data movement, keep time-sensitive decisions local and enable deep analysis across operations.
Key takeaways:
Edge hardware executes immediate decisions to prevent equipment damage and localized safety hazards.
Cloud servers handle large-scale data aggregation, historical modeling and cross-site benchmarking.
A hybrid method helps control recurring data transfer bills while keeping localized actions instantaneous.
Organizations can reduce human capital expenses by using automated remote updates to maintain local algorithms.
Lou Farrell
This article was contributed by Lou Farrell, a guest author and the senior editor of technology and AI/Cloud computing at Revolutionized Magazine. For several years, Lou has leveraged his deep understanding of the transformative potential of AI and IoT to craft engaging and insightful pieces that analyze their impact on today’s connected world. His work aims to educate and inform readers on navigating the complexities of modern industrial technology.
Relevant to your operations?
We typically respond within 24 hours
%3Aformat(webp)&w=3840&q=75)



